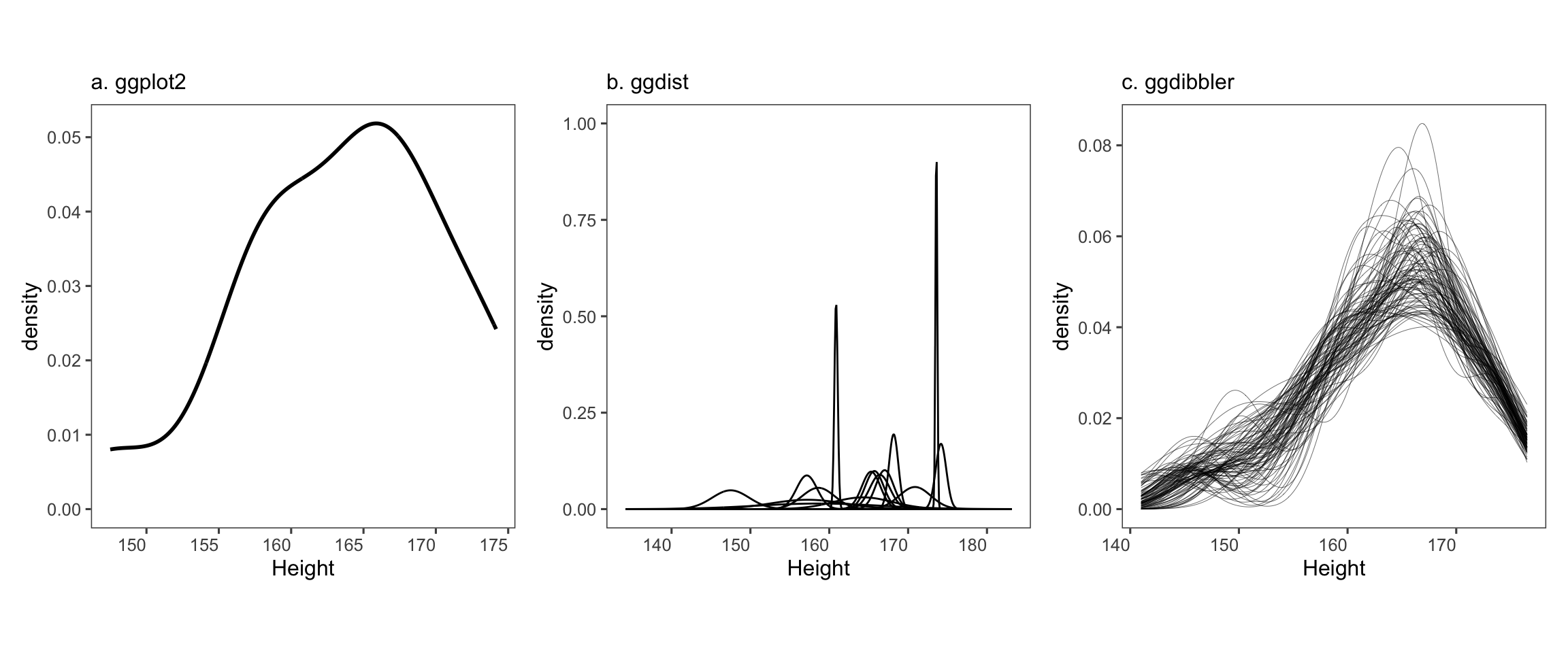
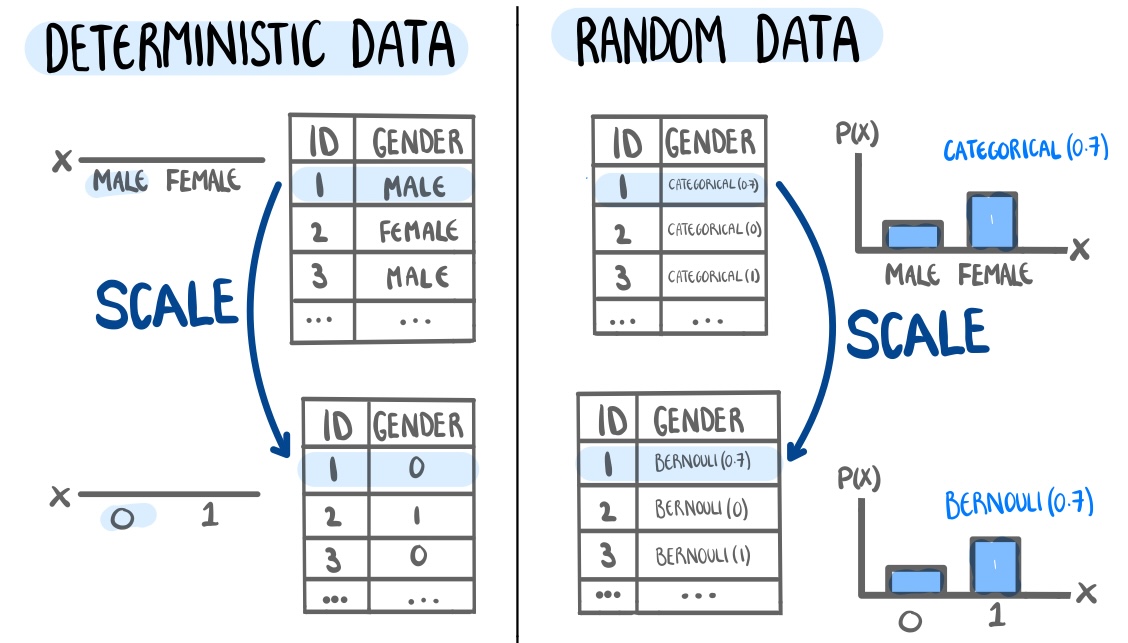
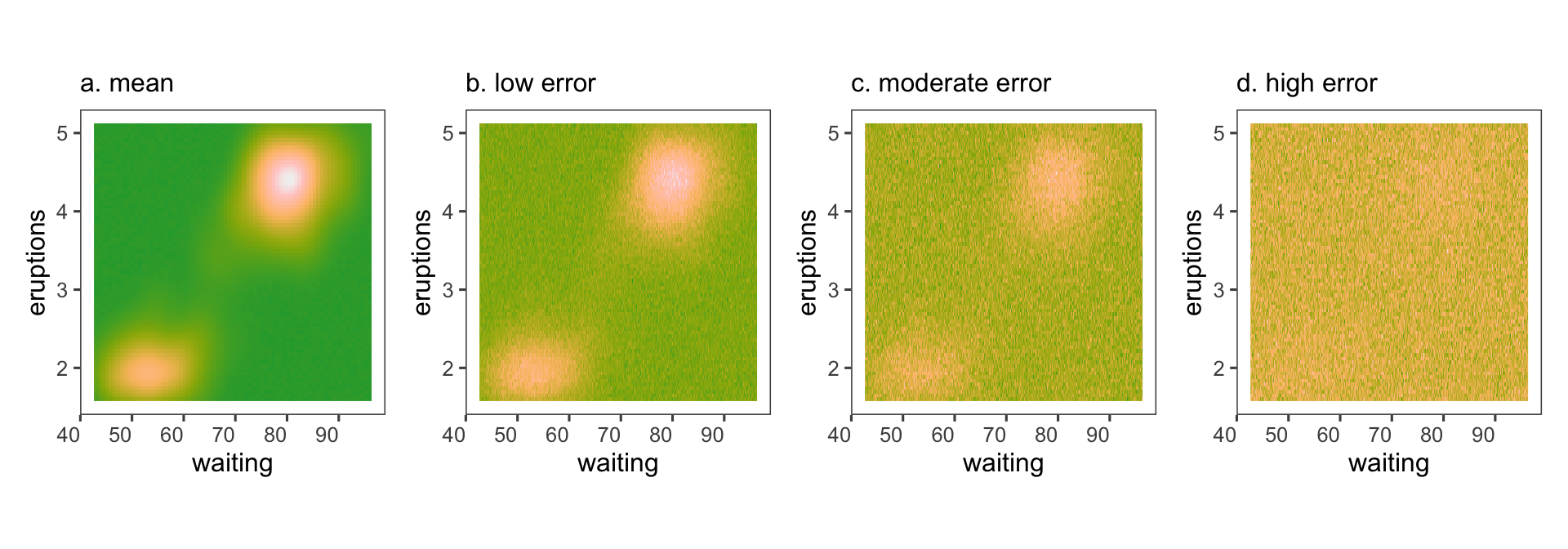
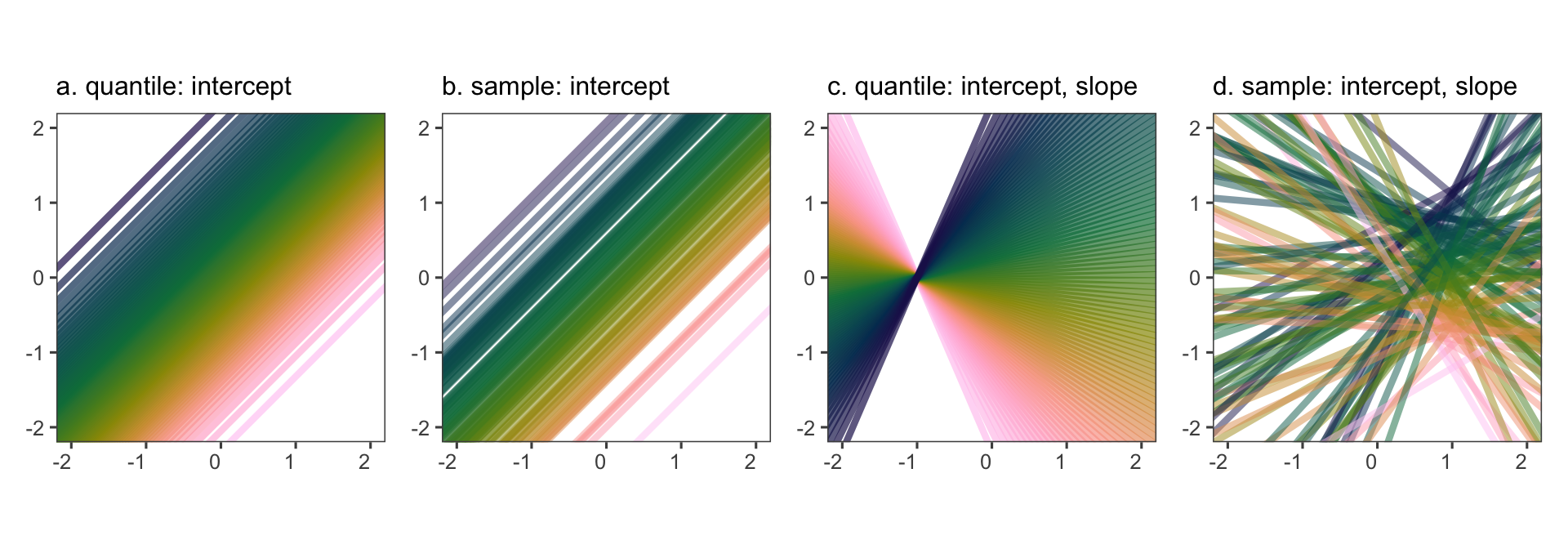
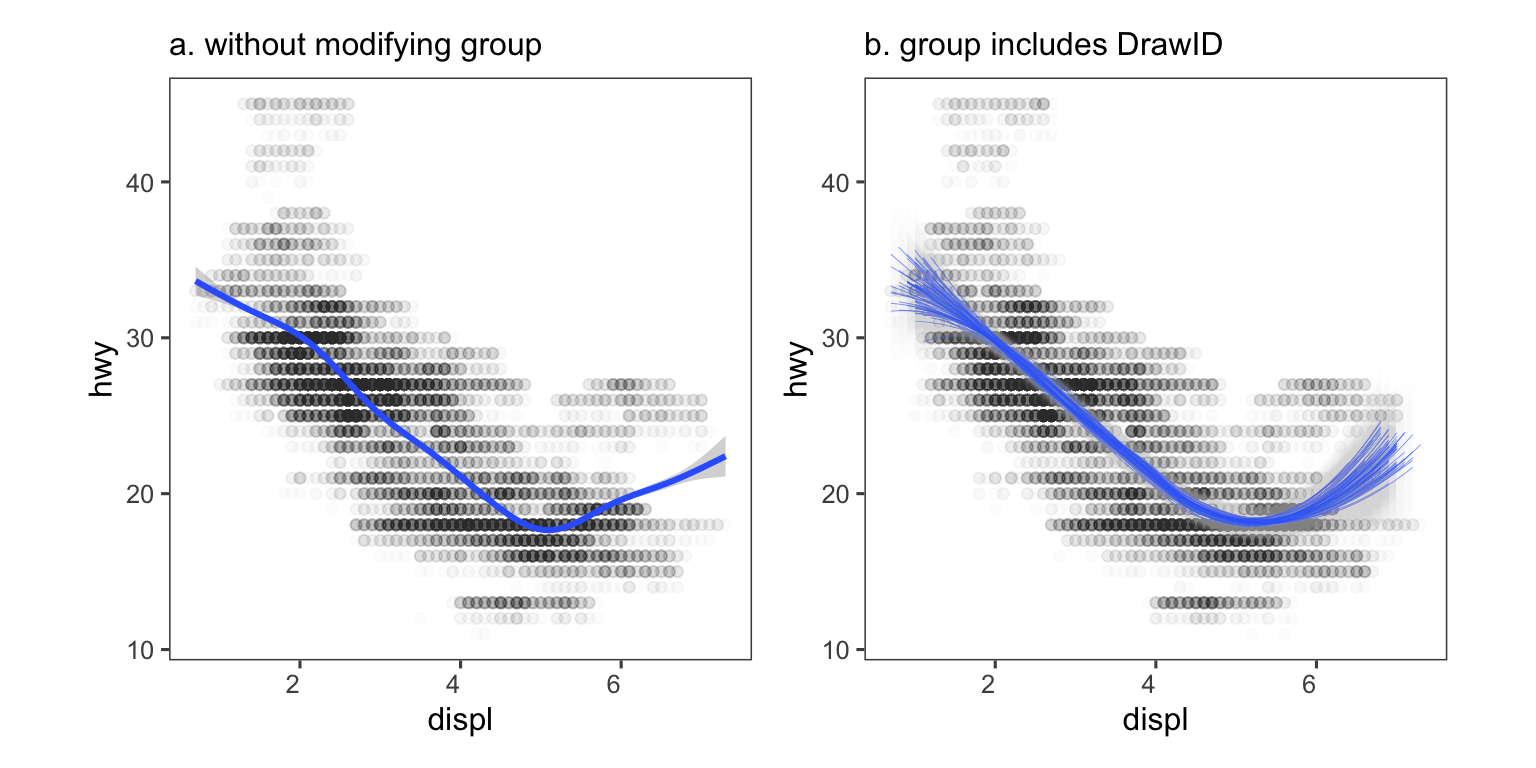
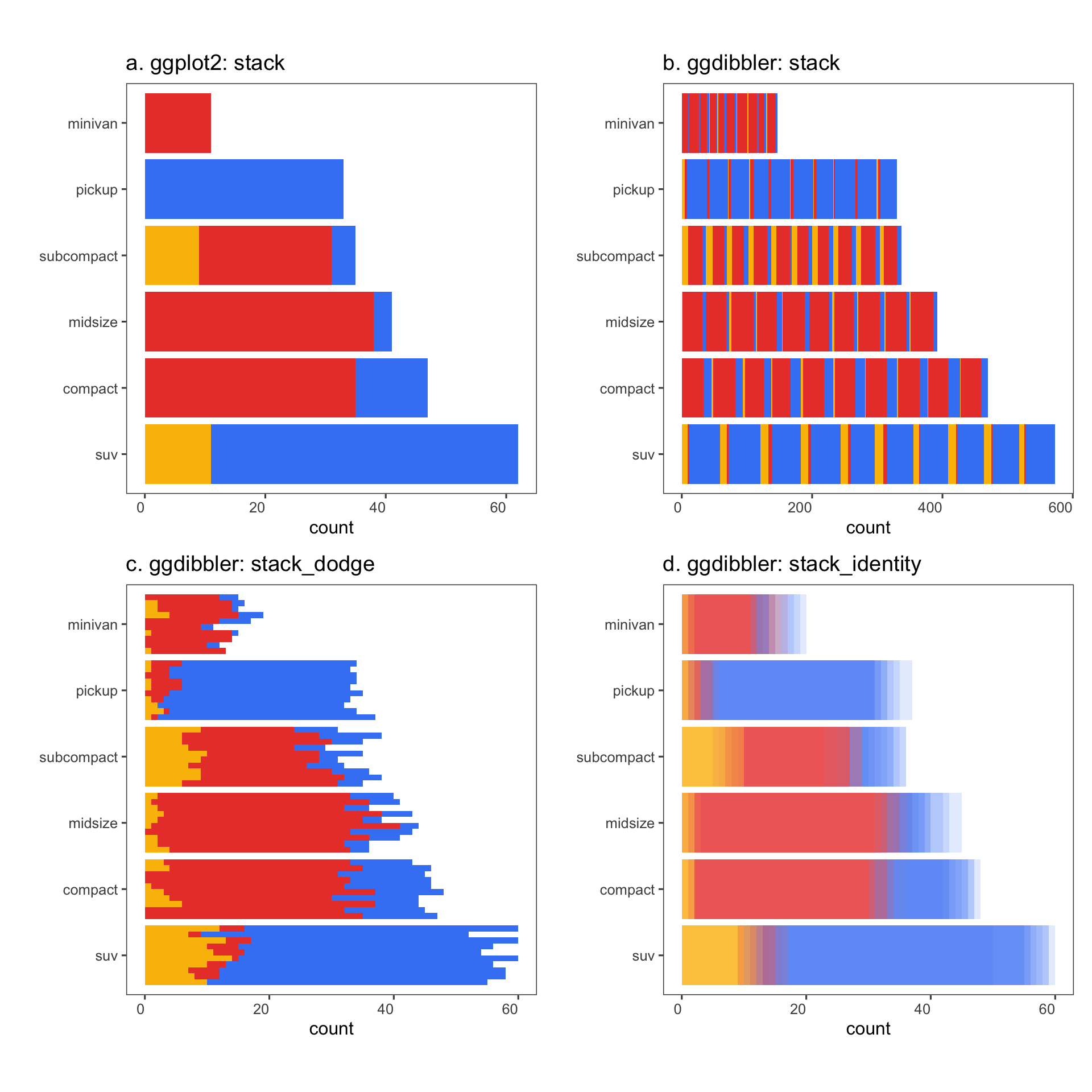
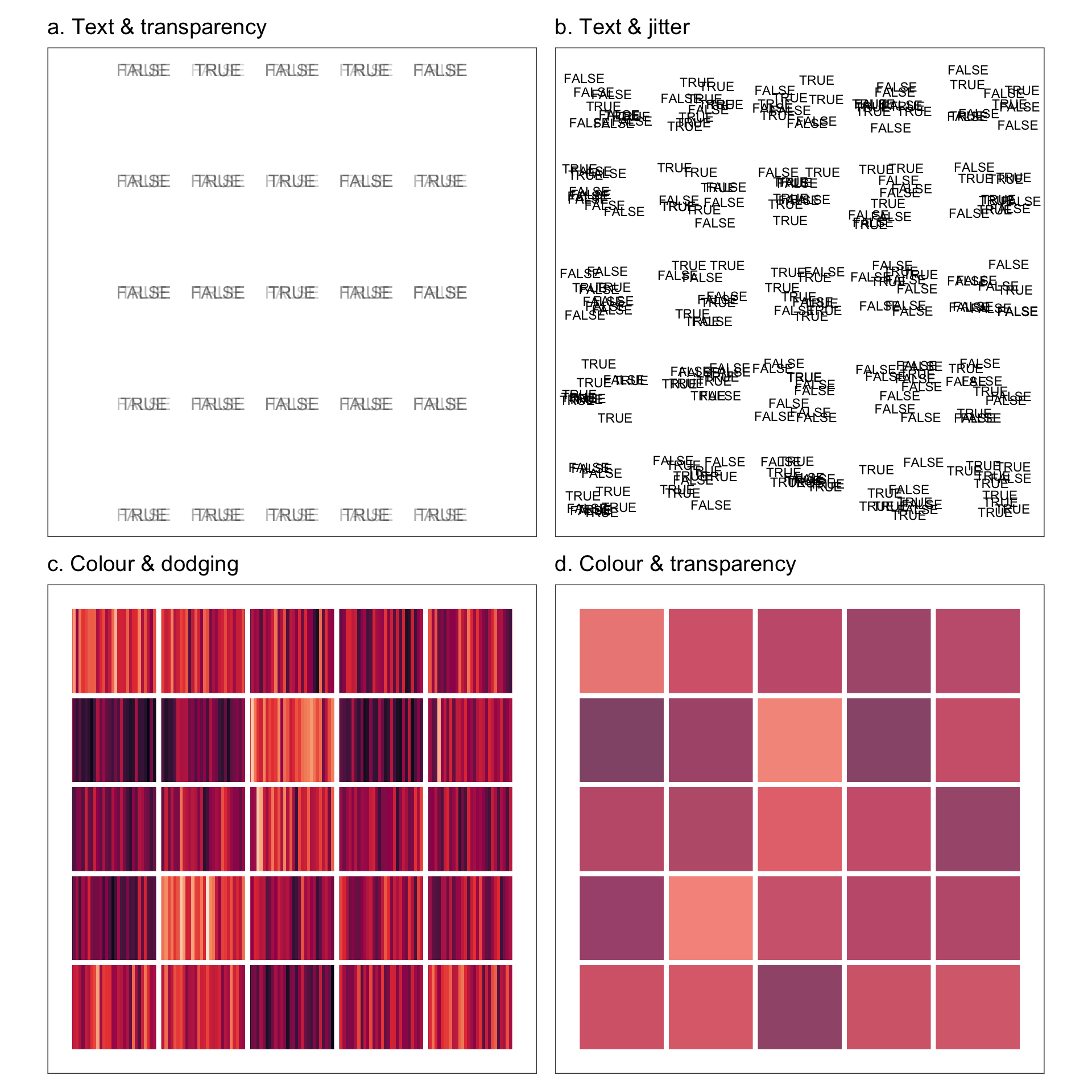
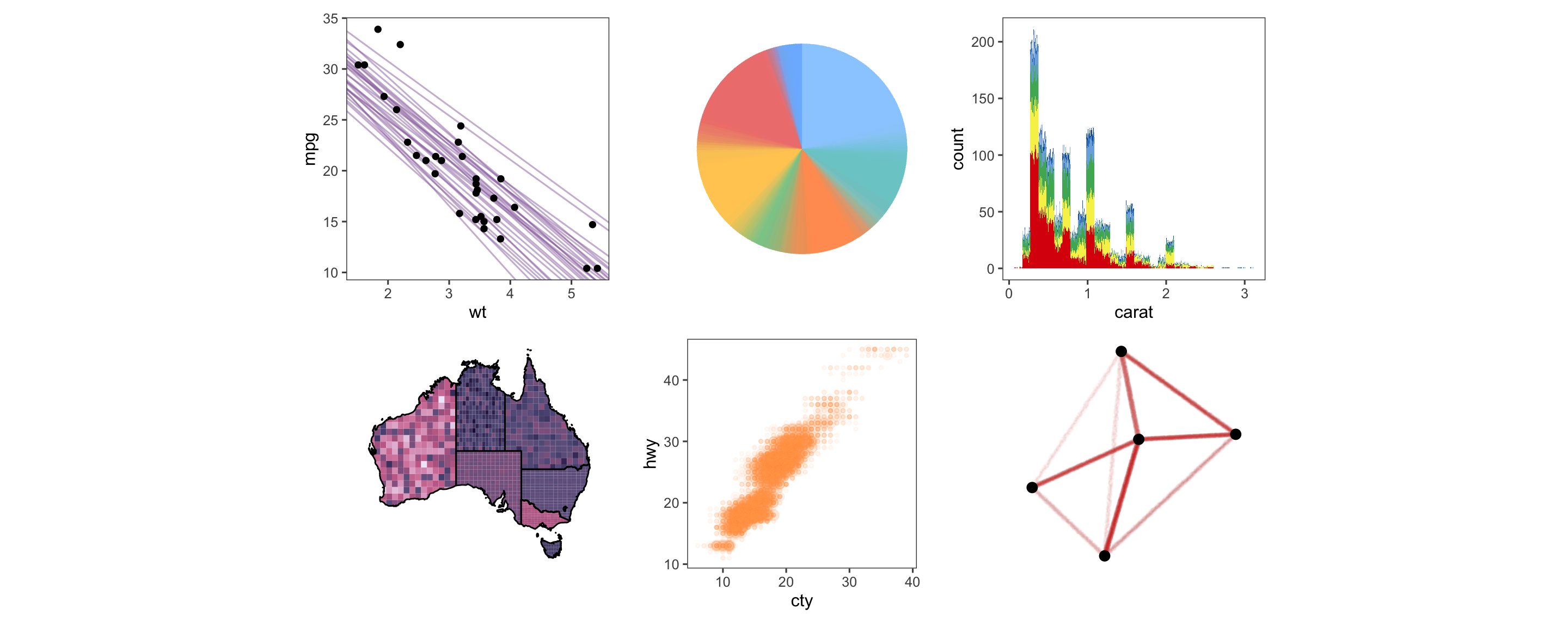
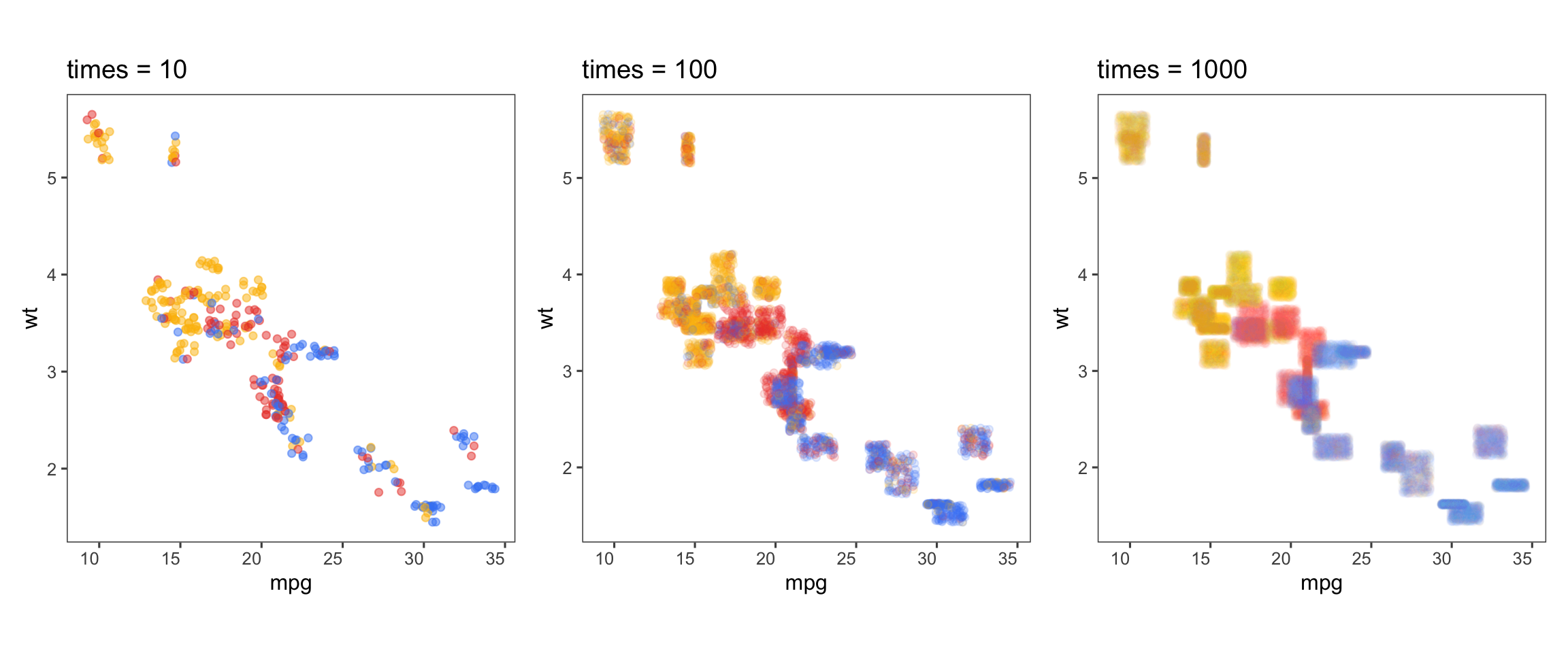
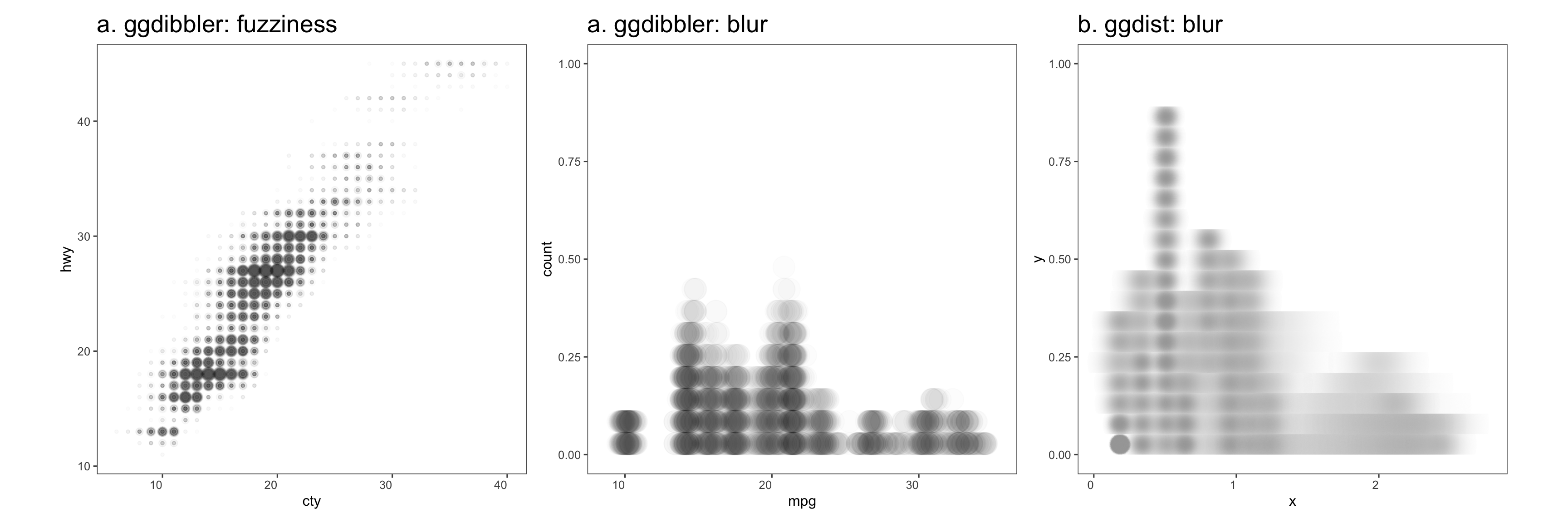
The first author of this paper is supported in part by a scholarship from the the Australian Energy Market Operator. This research was supported by the Commonwealth through an Australian Government Research Training Program Scholarship [DOI: https://doi.org/10.82133/C42F-K220]. The first author would also like to thank Mitchell O’Hara-Wild and Cynthia Huang for their comments and feedback which substantially improved the work, as well as Ze-Yu Zhong for several interesting examples that ended up being used in this paper. The R packages used for this work were: tidyverse (Wickham et al. 2019), distributional (O’Hara-Wild et al. 2024), ggdist (Kay 2023), ggdibbler (Mason et al. 2026b), patchwork (Pedersen 2025a), khroma (Frerebeau 2025), tidygraph (Pedersen 2024), colourspace (Stauffer et al. 2009), ggraph (Pedersen 2025b), ozmaps (Sumner 2021), sf (Pebesma 2018), and ggthemes (Arnold 2024). The GitHub repository for this paper can be found at https://github.com/harriet-mason/paper-ggdibbler, which contains the files required to reproduce this article in full.
Arnold, J. B. (2024),
ggthemes: Extra themes, scales and geoms for ’ggplot2’.
https://doi.org/10.32614/CRAN.package.ggthemes.
Bartonicek, A., Urbanek, S., and Murrell, P. (2025),
“No more, no less than sum of its parts: Groups, monoids, and the algebra of graphics, statistics, and interaction,” Journal of Computational and Graphical Statistics, 34, 1063–1074.
https://doi.org/10.1080/10618600.2024.2429708.
Bornkamp, B. (2018),
“Calculating quantiles of noisy distribution functions using local linear regressions,” Computational Statistics, Springer, 33, 487–501.
https://doi.org/10.1007/s00180-017-0736-0.
Buja, A., Cook, D., Hofmann, H., Lawrence, M., Lee, E. K., Swayne, D. F., and Wickham, H. (2009),
“Statistical inference for exploratory data analysis and model diagnostics,” Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, Royal Society, 367, 4361–4383.
https://doi.org/10.1098/rsta.2009.0120.
Cook, D., Lee, E.-K., and Majumder, M. (2016),
“Data visualization and statistical graphics in big data analysis,” Annual Review of Statistics and Its Application, 3, 133–159.
https://doi.org/10.1146/annurev-statistics-041715-033420.
Correll, M., Moritz, D., and Heer, J. (2018),
“Value-suppressing uncertainty palettes,” Conference on Human Factors in Computing Systems - Proceedings, 2018-April, 1–11.
https://doi.org/10.1145/3173574.3174216.
Csárdi, G. (2025),
cli: Helpers for developing command line interfaces.
https://doi.org/10.32614/CRAN.package.cli.
Frerebeau, N. (2025),
khroma: Colour schemes for scientific data visualization, Pessac, France: Université Bordeaux Montaigne.
https://doi.org/10.5281/zenodo.1472077.
Gentleman, R. C., Carey, V. J., Bates, D. M., and others (2004),
“Bioconductor: Open software development for computational biology and bioinformatics,” Genome Biology, 5, R80.
https://doi.org/10.1186/gb-2004-5-10-r80.
Guo, Z., Kale, A., Kay, M., and Hullman, J. (2025),
“VMC: A grammar for visualizing statistical model checks,” IEEE Transactions on Visualization and Computer Graphics, IEEE Educational Activities Department, 31, 798–808.
https://doi.org/10.1109/TVCG.2024.3456402.
Hadjimichael, A., Schlumberger, J., and Haasnoot, M. (2024),
“Data visualisation for decision making under deep uncertainty: Current challenges and opportunities,” Environmental Research Letters, 19, 111011.
https://doi.org/10.1088/1748-9326/ad858b.
Henry, L., and Wickham, H. (2026a),
rlang: Functions for base types and core r and ’tidyverse’ features.
https://doi.org/10.32614/CRAN.package.rlang.
Henry, L., and Wickham, H. (2026b),
lifecycle: Manage the life cycle of your package functions.
https://doi.org/10.32614/CRAN.package.lifecycle.
Hullman, J., and Gelman, A. (2021),
“Designing for interactive exploratory data analysis requires theories of graphical inference,” Harvard Data Science Review, 1–70.
https://doi.org/10.1162/99608f92.3ab8a587.
Hullman, J., Resnick, P., and Adar, E. (2015),
“Hypothetical outcome plots outperform error bars and violin plots for inferences about reliability of variable ordering,” PLoS ONE, Public Library of Science, 10.
https://doi.org/10.1371/journal.pone.0142444.
Kay, M. (2023), “ggdist: Visualizations of distributions and uncertainty in the grammar of graphics,” IEEE Transactions on Visualization and Computer Graphics, IEEE, 30, 414–424.
Luce, R. D., and Edwards, W. (1958), “The derivation of subjective scales from just noticeable differences.” Psychological review, American Psychological Association, 65, 222.
MacEachren, A. M. (1992),
“Visualizing uncertain information,” Cartographic Perspectives, 10–19.
https://doi.org/10.14714/CP13.1000.
MacEachren, A. M., Robinson, A., Hopper, S., Gardner, S., Murray, R., Gahegan, M., and Hetzler, E. (2005),
“Visualizing geospatial information uncertainty: What we know and what we need to know,” Cartography and Geographic Information Science, 32, 139–160.
https://doi.org/10.1559/1523040054738936.
Majumder, M., Hofmann, H., and Cook, D. (2013),
“Validation of visual statistical inference, applied to linear models,” Journal of the American Statistical Association, 108, 942–956.
https://doi.org/10.1080/01621459.2013.808157.
Mann, H. B., and Wald, A. (1943),
“On stochastic limit and order relationships,” The Annals of Mathematical Statistics, 14, 217–226.
https://doi.org/10.1214/aoms/1177731415.
Mason, H., Cook, D., Goodwin, S., Tanaka, E., and VanderPlas, S. (2026a),
“The noisy work of uncertainty visualisation research.”
Mason, H., Cook, D., Goodwin, S., and VanderPlas, S. (2026b),
ggdibbler: Add uncertainty to data visualisations.
https://doi.org/10.32614/CRAN.package.ggdibbler.
McNutt, A., Kindlmann, G., and Correll, M. (2020),
“Surfacing visualization mirages,” in
Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu HI USA: ACM, pp. 1–16.
https://doi.org/10.1145/3313831.3376420.
Müller, K., and Wickham, H. (2025),
tibble: Simple data frames.
https://doi.org/10.32614/CRAN.package.tibble.
O’Hara-Wild, M., Kay, M., Hayes, A., and Hyndman, R. (2024),
distributional: Vectorised probability distributions.
https://doi.org/10.32614/CRAN.package.distributional.
Padilla, L., Kay, M., and Hullman, J. (2022), “Uncertainty visualization,” in Computational Statistics in Data Science, eds. W. W. Piegorsch, R. A. Levine, H. H. Zhang, and T. C. M. Lee, Hoboken, NJ: John Wiley & Sons, pp. 405–426.
Pebesma, E. (2018),
“Simple Features for R: Standardized support for spatial vector data,” The R Journal, 10, 439–446.
https://doi.org/10.32614/RJ-2018-009.
Pedersen, T. L. (2024),
tidygraph: A tidy API for graph manipulation.
https://doi.org/10.32614/CRAN.package.tidygraph.
Pedersen, T. L. (2025a),
patchwork: The composer of plots.
https://doi.org/10.32614/CRAN.package.patchwork.
Pedersen, T. L. (2025b),
ggraph: An implementation of grammar of graphics for graphs and networks.
https://doi.org/10.32614/CRAN.package.ggraph.
Peña-Araya, V., Fontaine, C. M., Wei, X., Delpech, G., and Bezerianos, A. (2025), “Uncertainty in science is malleable. Advocating for user-agency in defining uncertainty in visualizations: A case study in geology,” in Proceedings of the 2025 CHI conference on human factors in computing systems, pp. 1–18.
Potter, K., Kniss, J., Riesenfeld, R., and Johnson, C. R. (2010),
“Visualizing summary statistics and uncertainty,” Computer Graphics Forum, 29, 823–832.
https://doi.org/10.1111/j.1467-8659.2009.01677.x.
Satyanarayan, A., Moritz, D., Wongsuphasawat, K., and Heer, J. (2016), “Vega-lite: A grammar of interactive graphics,” IEEE Transactions on Visualization and Computer Graphics, IEEE, 23, 341–350.
Savvides, R., Henelius, A., Oikarinen, E., and Puolamäki, K. (2019),
“Significance of patterns in data visualisations,” in
Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage AK USA: Association for Computing Machinery, pp. 1509–1517.
https://doi.org/10.1145/3292500.3330994.
Stauffer, R., Mayr, G. J., Dabernig, M., and Zeileis, A. (2009),
“Somewhere over the rainbow: How to make effective use of colors in meteorological visualizations,” Bulletin of the American Meteorological Society, 96, 203–216.
https://doi.org/10.1175/BAMS-D-13-00155.1.
Sumner, M. (2021),
ozmaps: Australia maps.
https://doi.org/10.32614/CRAN.package.ozmaps.
Swihart, B. J., Caffo, B., James, B. D., Strand, M., Schwartz, B. S., and Punjabi, N. M. (2010), “Lasagna plots: A saucy alternative to spaghetti plots,” Epidemiology, LWW, 21, 621–625.
Wickham, H. (2010),
“A layered grammar of graphics,” Journal of Computational and Graphical Statistics, 19, 3–28.
https://doi.org/10.1198/jcgs.2009.07098.
Wickham, H. (2019),
Advanced R, Chapman; Hall/CRC.
https://doi.org/10.1201/9781351201315.
Wickham, H., Averick, M., Bryan, J., Chang, W., D’Agostino McGowan, L., François, R., Grolemund, G., Hayes, A., Henry, L., Hester, J., Kuhn, M., Pedersen, T. L., Miller, E., Bache, S. M., Müller, K., Ooms, J., Robinson, D., Seidel, D. P., Spinu, V., Takahashi, K., Vaughan, D., Wilke, C., Woo, K., and Yutani, H. (2019),
“Welcome to the tidyverse,” Journal of Open Source Software, 4, 1686.
https://doi.org/10.21105/joss.01686.
Wickham, H., François, R., Henry, L., Müller, K., and Vaughan, D. (2023),
dplyr: A grammar of data manipulation.
https://doi.org/10.32614/CRAN.package.dplyr.
Wickham, H., Lawrence, M., Cook, D., Buja, A., Hofmann, H., and Swayne, D. F. (2009), “The plumbing of interactive graphics,” Computational Statistics, Springer, 24, 207–215.
Wickham, H., Pedersen, T. L., and Seidel, D. (2025a),
scales: Scale functions for visualization.
https://doi.org/10.32614/CRAN.package.scales.
Wickham, H., Vaughan, D., and Girlich, M. (2025b),
tidyr: Tidy messy data.
https://doi.org/10.32614/CRAN.package.tidyr.
Wilkinson, L. (2005),
The grammar of graphics, Berlin, Heidelberg: Springer-Verlag.
https://doi.org/10.1007/0-387-28695-0.
Zhang, M., and Lin, D. K. J. (2022),
“Visualization for interval data,” Journal of Computational and Graphical Statistics, 31, 960–975.
https://doi.org/10.1080/10618600.2022.2066678.